检索增强微调:使用 GPT-4o 微调 GPT-4o mini 模型以适用于特定领域应用
对企业来说,生成式AI最具影响力的应用之一是创建自然语言界面,这些界面已根据特定领域和使用场景的数据进行了定制,以提供更准确、更准确的响应。这意味着回答与银行、法律和医疗等特定领域相关的问题。
我们经常谈到实现这一目标的两种方法:
- 检索增强生成(RAG):将这些文档存储在向量数据库中,在查询时根据它们与问题的语义相似度来检索文档,然后将它们作为LLM的上下文。
- 监督微调(SFT):在一组代表特定领域知识的提示和响应上对现有的基线模型进行训练。
虽然大多数尝试使用RAG的组织都试图通过其内部知识库来扩展LLM的知识,但许多组织在没有进行显著优化的情况下未能达到预期效果。同样,精心挑选一个足够大且高质量的数据集用于微调也是一项具有挑战性的任务。这两种方法都有局限性:微调将模型限制在其已训练的数据上,使其容易受到近似和幻觉的影响,而RAG虽然可以使模型落地,但它仅根据查询与文档的语义接近程度来检索文档——这可能与查询无关,并导致给出的解释不充分。
与其纠结于二选一,不如组合它们试试!可以将RAG看作是一场开卷考试:模型会查找相关的文档来生成答案。微调则像是闭卷考试:模型依赖于预先训练的知识。那么考试最好的成绩将基于运用好学习的知识和准备的笔记。
检索增强微调(RAFT)是一种强大的技术,用于为特定领域的开放式环境(如域内RAG)准备微调数据。对于语言模型来说,RAFT是一项具有变革性的技术,它结合了RAG和微调的优点。RAFT通过增强模型理解和使用特定领域知识的能力,帮助模型适应特定领域。它是RAG和域特定微调之间的完美平衡点。
RAFT有三个步骤:
- 准备数据集,让模型学习如何回答与您的领域相关的问题。
- 使用您准备好的数据集对模型进行微调
- 评估您新创建的、自定义的、适配特定领域的模型的质量
RAFT的关键在于训练数据的生成,其中每个数据点包括一个问题(Q)、一组文档(Dk)和一种“思维链”风格的答案(A)。
这些文件被分为两类:标准参考文件(Do),其中包含答案;以及干扰文件(Di),其中不包含答案。微调使模型能够区分这两种文件,从而生成一个定制模型,其性能优于仅使用RAG或微调的原始模型。
我们使用GPT-4o生成训练数据并微调GPT-4o mini版,以创建适合您的具体需求的成本效益更高、速度更快的模型。这种技术称为蒸馏,其中GPT-4o作为教师模型,4o-mini作为学生。
接下来我们将动手操作。如果您想自行跟随操作或查看参考代码,请访问https://aka.ms/aoai-raft-workshop。我们将为一个银行业务场景创建一个自定义模型,能够回答有关银行在线工具和账户的问题。
生成 RAFT 训练数据
首先收集特定领域的文档,例如银行文件的PDF格式。为了生成我们的训练数据,我们将PDF文件转换为Markdown文本格式。该文档为PDF格式,包含许多表格和图表,我们将使用GPT-4o将页面内容转换为Markdown格式。我们使用 Azure OpenAI GPT-4o 将所有这些信息提取到一个Markdown文件中,用于下游处理。然后,我们使用GPT-4o(我们的教师模型)生成合成的“问题-文档-答案”三元组,包括“黄金文档”(高度相关)和“干扰项”(误导性)的例子。这将确保模型能够区分相关和无关信息。RAFT采用“思维链”(CoT)过程,通过整合CoT过程,RAFT过程可以提高模型提取信息和进行逻辑推理的能力。这种方法有助于防止过拟合,提高训练的健壮性,特别适用于需要详细结构化思维的任务。然后我们将这些数据进行格式化,以便进行微调,并将其分为训练、验证和测试集。验证数据在训练过程中使用,而测试集则用于在训练结束后评估性能。
RAFT 微调
在准备完训练数据和验证数据后,下一步是将这些数据上传到 Azure OpenAI 并创建微调任务。这非常简单:在 AI Studio 中,选择您的模型,上传您的训练数据和验证数据,并设置您的训练参数只需几步即可。我们将选择 4o-mini 作为我们的训练模型。在实验室里,我们会向您展示如何使用SDK上传和触发微调作业。UI提供了一种易于实验的方法,而SDK的方法则是在生产环境中实现和启用LLMops部署策略的首选方式。
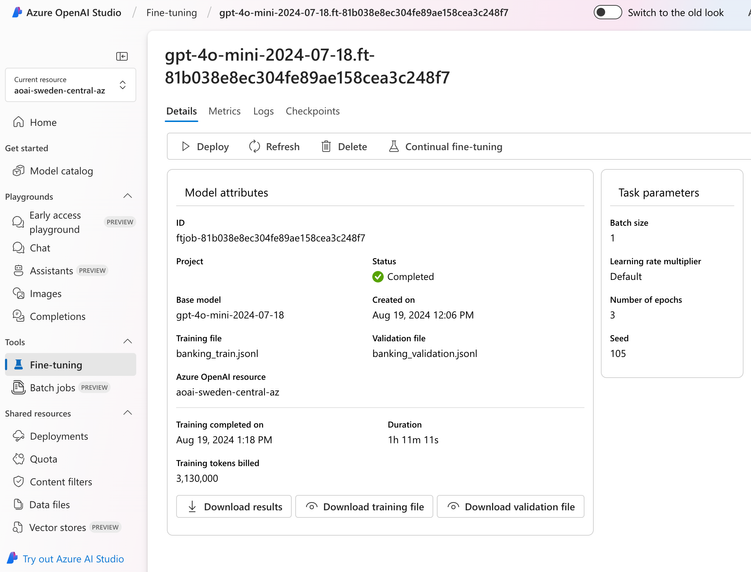
一旦微调工作开始运行,我们可以监控其进度,完成后,可以在 Azure OpenAI Studio 中分析微调后的模型。最后,我们创建一个新的部署,其中包含微调后的模型,可用于我们的专业领域任务。
评估 RAFT 模型
你可以从查看AI Studio提供的内置指标开始,查看损失和准确率。我们希望看到准确率不断提高,而损失不断降低:

然而我们可以做更多事情来衡量模型的质量。还记得一开始我们准备的测试数据集吗?这就是我们准备它的原因!
虽然有很多评估选项,包括 AI Studio 评估,但在我们的示例中,我们使用了开源库 RAGAS,它使用诸如“答案相关性”、“真实性”、“答案相似度”和“答案正确性”等指标来评估 RAG 管道。这些指标依赖于语言模型作为评判者或嵌入式模型来评估生成答案的质量和准确性。
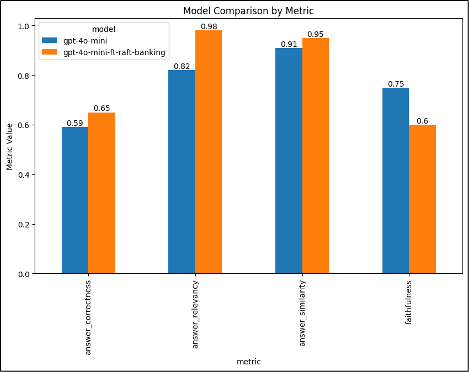
gpt4o-mini vs gpt4o-mini-raft
我们可以通过调整训练参数或生成更多的训练数据来进一步提升我们的指标。
- 本文作者:BeanHsiang
- 本文链接:https://beanhsiang.github.io/post/2024-09-08-retrieval-augmented-fine-tuning-use-gpt-4o-to-fine-tune-gpt-4o/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. 进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。