使用 Semantic Kernel 插件编排 AI 代理的技术深度解析
在如今快速发展的 大型语言模型(LLM) 领域,编排专门的 AI 代理已成为构建复杂认知系统的关键,这些系统能够进行复杂推理和任务执行。虽然功能强大,但协调多个具有独特能力和数据访问权限的代理会带来显著的工程挑战。微软的 Semantic Kernel(SK)通过其直观的插件系统为管理这种复杂性提供了强大的框架。本文将深入探讨如何利用 SK 插件实现高效的代理编排,并结合实际实现模式进行说明。
代理编排的挑战
现代 AI 应用通常超越单一 LLM 的能力,越来越依赖专业代理团队的协作。例如,一个查询可能需要获取以下信息:
- 一个代理访问内部政策文档
- 另一个代理搜索公共网络
- 第三个代理查询私有数据库
编排这些代理的核心挑战如下:
- 动态选择:适合特定任务的代理。
- 管理上下文和数据流:在各代理之间。
- 综合潜在冲突的输出:形成连贯的最终响应。
- 保持模块化和可观察性:随着系统规模扩大。
Semantic Kernel 插件
Semantic Kernel 的插件架构提供了一个结构化解决方案。插件作为代理功能的标准化封装,允许 Kernel(中央编排器) 有效地发现、调用和管理这些功能。其主要优势包括:
- 模块化代理集成:每个代理的逻辑封装在专属的插件中。
- 声明式调用:通过对插件功能的清晰描述实现动态选择和调用。
- 统一接口:标准化代理间的交互方式。
- 集中监控:跟踪资源使用(如 token 消耗)和执行流程。
- 简化结果整合:提供钩子以合并多个代理的输出为一致的响应。
架构概览
使用 Semantic Kernel 插件构建的编排系统架构如下:
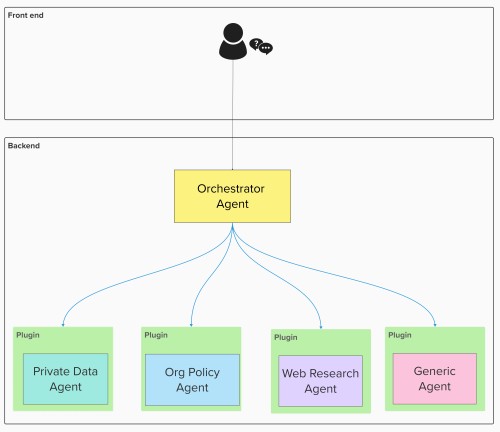
这一架构包括:
- 中央编排代理:由 SK 驱动,通过接收用户查询管理代理调用。
- 专门代理插件:每个插件暴露特定代理功能(如 Web 搜索、内部文件访问等)。
- 插件注册机制:支持动态发现和调用所需的代理功能。
- 结果整合逻辑:将多代理输出转化为用户可读的统一响应。Kernel使用每个插件中提供的描述(通过
@kernel_function等装饰器)来确定哪些插件与用户查询相关,实现动态、上下文感知的代理调用。
编排代理的 Python 示例
以下代码展示了如何利用 Semantic Kernel SDK 实现一个简单的编排代理:
|
|
插件实现细节:Web Search Plugin
以下代码展示了 Web 搜索插件的具体实现:
|
|
插件的设计原则
- 清晰的功能定义:通过
@kernel_function装饰器协助 LLM 确定插件的使用场景。 - 标准化接口:抽象具体实现细节,提高系统的模块化。
- 结果处理逻辑:将外部搜索结果转化为编排器期望的格式。
插件编排的优势
利用 Semantic Kernel 插件进行代理编排,能够显著提升系统能力:
- 动态和上下文感知:根据用户查询和上下文动态选择最相关的代理。
- 灵活执行模式:支持并行和顺序调用,可适应复杂任务。
- 资源监控:集中管理所有代理的 token 使用情况,优化整体性能。
层级插件结构
Semantic Kernel 支持以层级方式组织插件,这可以反映复杂的代理交互:
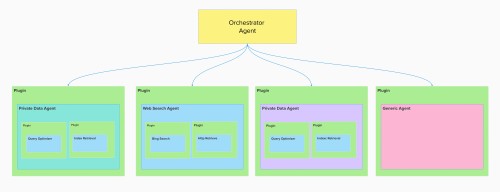
一个 AgentInvokingPlugin 可能在内部使用其他更细粒度的插件(例如 BingSearchPlugin 或 HttpRequestPlugin)。这允许在代理抽象中组合和重用低级功能。
插件式编排的强大优势
1. 动态和上下文感知的代理选择
Kernel 的 LLM 充当智能路由器,使用函数描述和对话历史为每个回合或子任务选择最相关的代理。system_prompt 指导这一选择过程:
|
|
2. 灵活的执行流程(并行/顺序)
SK 支持不同的函数调用模式。您可以配置 Kernel 以:
- 如果任务彼此独立,可以并行调用多个插件
- 如果一个代理的输出需要作为另一个代理的输入,则可以顺序链接插件调用
- 允许 LLM 自动决定最佳执行策略
3. 统一资源监控
通过让插件向编排器报告其令牌使用情况和执行时间,您可以获得对整个多代理系统中的成本和性能瓶颈的集中可见性。
实现模式
1. 代理调用插件的基类
创建一个基类来处理通用逻辑,如 kernel/message 存储、运行时访问、状态跟踪(调用状态、token 使用情况、结果)和结果处理。
|
|
2. 描述性插件和函数命名
为插件注册(plugin_name="WEB_SEARCH_AGENT")和 Kernel 函数(@kernel_function(name="invoke_web_search_agent", ...))使用清晰、描述性的名称。这有助于 LLM 理解和人工调试。
3. 显式函数选择配置
利用 FunctionChoiceBehavior(或特定 SK SDK 版本中的类似机制)来控制 LLM 如何选择和执行函数(例如,Auto 用于动态选择,Required 用于强制特定函数调用)。
使用 SK 插件进行代理编排的最佳实践
- 丰富的函数描述:为
@kernel_function编写详细、明确的描述。这对于准确的动态路由至关重要。 - 清晰的系统提示:指导编排器 LLM 了解总体目标、可用工具以及如何在它们之间进行选择。
- 标准化输入/输出:设计插件函数接受简单输入(如字符串)并返回标准化、可预测的输出(或可预测地更新状态)。
- 强大的错误处理:在插件函数中实现 try/except 块,并向编排器清晰报告错误。
- 全面的遥测:记录关键事件(插件调用、代理请求/响应、错误、计时)以进行监控和调试。使用关联 ID。
- 状态管理:仔细管理传递给插件的共享状态(如对话历史)以及插件如何更新聚合结果(令牌、引用)。
- 可观察性优先:从一开始就考虑日志和指标设计插件。跟踪每个插件/代理的令牌使用情况。
- 代理契约测试:为每个插件实现测试,模拟底层代理,确保其符合预期接口和行为。
- 幂等性考虑:如果代理可能被重试,考虑设计其操作尽可能具有幂等性。
- 断路器:为可能不可靠或缓慢的外部代理调用实现弹性模式,如断路器。
结论
Semantic Kernel 插件为 AI 代理编排的复杂挑战提供了强大且结构化的方法。通过在标准化插件框架内封装代理功能,开发人员可以构建复杂的多代理系统,受益于:
- 模块化:更容易的开发、测试和维护。
- 动态路由:智能、上下文感知的专门代理选择。
- 可扩展性:添加新代理功能的清晰模式。
- 可观察性:性能和资源消耗的集中监控。
随着 AI 应用越来越依赖专门代理的协作,掌握像 Semantic Kernel 这样的插件式编排框架将对构建下一代智能、强大且可维护的系统至关重要。
参考链接
- 本文作者:BeanHsiang
- 本文链接:https://beanhsiang.github.io/post/2025-05-08-a-technical-deep-dive-into-orchestrating-ai-agents-using-semantic-kernel-plugins/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. 进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。