使用 Microsoft Agent Framework 构建 Human-in-the-loop 的 AI 工作流
一个把确定性编排与自主代理结合起来的欺诈检测示例
现代企业系统经常面临一个非常现实的问题:如何让 AI 的决策可靠、可解释,并且真正能在生产环境落地?
原文围绕一个“欺诈检测(Fraud Detection)”示例,展示了 Microsoft Agent Framework 如何把 AI 驱动的推理步骤放进一个可控的工作流里:
- 工作流图(workflow graph)负责确定性编排:控制执行顺序、并行与合流、容错与恢复
- 专家代理(agents)负责LLM 推理:在结构化/半结构化数据上做领域判断
完整实现代码仓库在这里:
为什么要把 Workflows 和 Agents 组合起来?
在金融、医疗、物流、客服等行业,AI 系统往往都遇到同一种核心矛盾:既要“聪明”(能理解复杂、模糊的数据),又要“可控”(能追溯、可复现、能稳定运维)。
- 规则/流程(rule-based workflows)擅长可预测、合规,但对变化的适应性弱。
- 纯代理(pure AI agents)能处理模糊复杂场景,但常缺少生产环境所需的保证:可复现性、可观测性、失败后的安全恢复等。
Microsoft Agent Framework 的思路是把两者优势拼起来:
- 确定性工作流图:管执行、管结构、管容错
- 自主代理:做最适合 LLM 的推理步骤
在欺诈检测里,这意味着工作流端到端编排流程,而不同的专家代理分别理解使用模式、地理位置异常、账单/收费异常等。
各司其职:
- Workflow: 结构化、类型安全、容错
- Agents: 领域推理与上下文洞察
系统架构
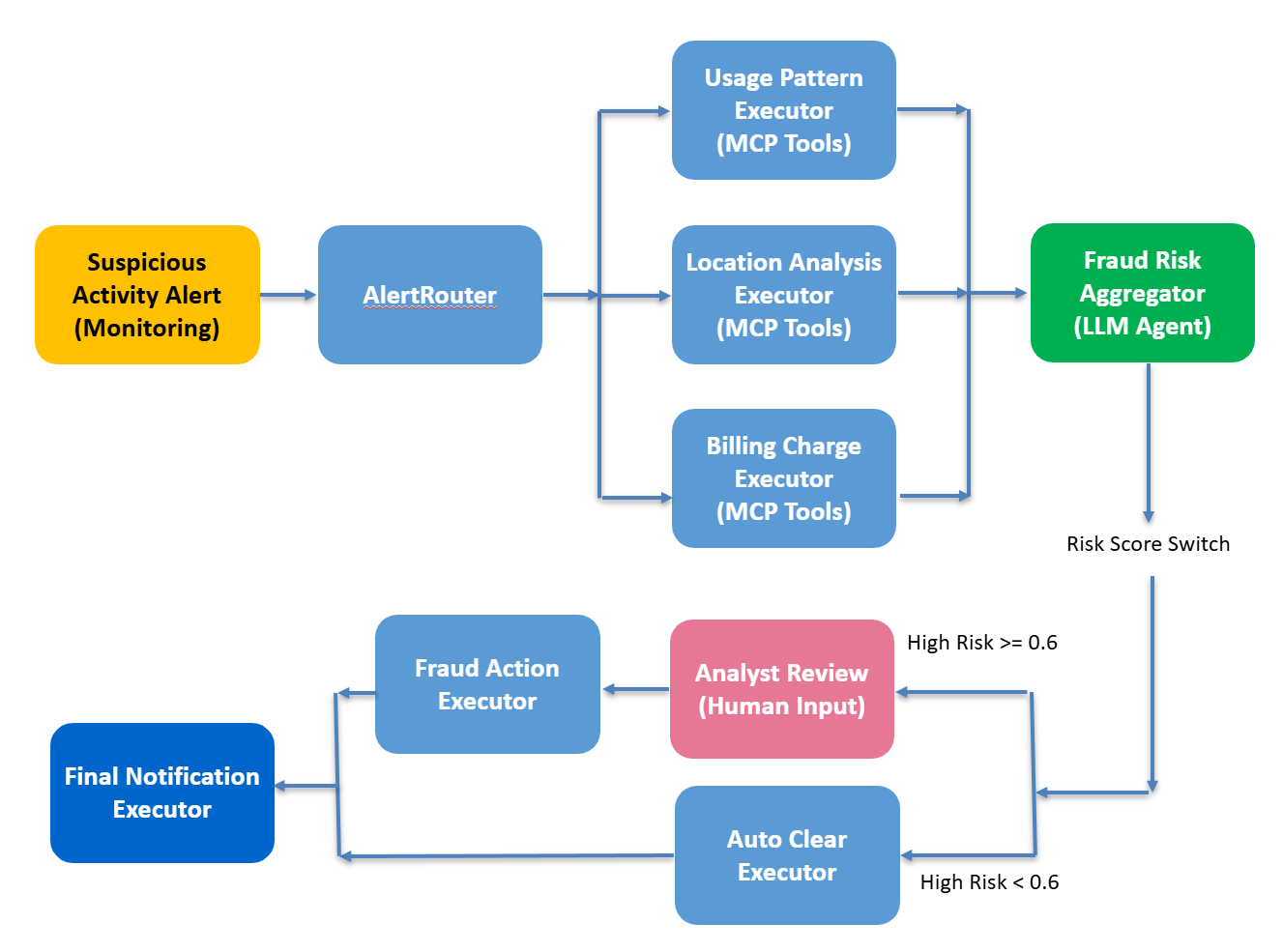
该欺诈检测 scenario 使用典型的 fan-out / fan-in 编排模式:
- fan-out:同时触发多个专家代理并行分析
- fan-in:汇总各分支结果,最后进行确定性决策
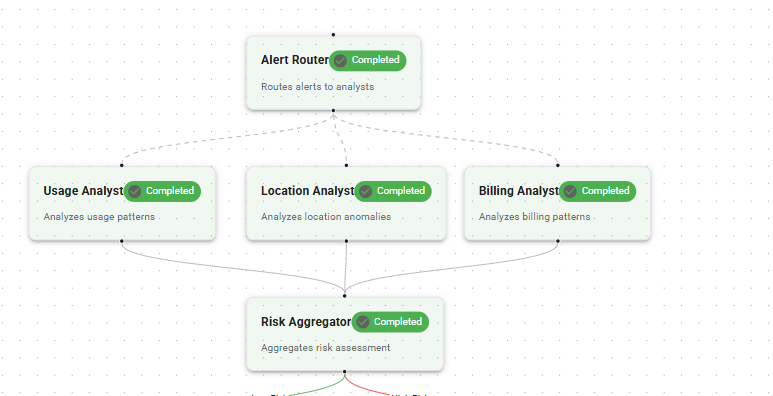
整体由四个组件构成:Alert Router、Specialist Agents、Fraud Risk Aggregator、Deterministic Decision Logic。
Alert Router
Alert Router 是工作流入口。当新告警到达时(例如:来自多个国家的登录尝试、交易突然激增),它会启动工作流并把任务并行分发给多个代理。它负责的是“编排”,而不是“解释数据”。
它通常会封装:
- 工作流初始化(告警接入与元数据记录)
- 上下文创建(customer ID、时间窗口、告警类型)
- 启动多个代理的并行执行
- fan-out 协调与错误传播处理
这一阶段是完全确定性的。
Specialist Agents(专家代理)
工作流中有三个领域代理,每个代理都通过 MCP(Model Context Protocol)被限制在严格的工具/数据访问范围内:
| Agent | 责任 | 示例数据访问 |
|---|---|---|
| UsagePatternAgent | 分析用量/行为异常 | 访问用量指标 API |
| LocationAgent | 检测地理位置不一致或异常登录来源 | GeoIP 查询或登录日志 |
| BillingAgent | 检视近期交易趋势与异常扣费 | 账单或支付服务 API |
这些代理在工作流运行时以“自主”的方式执行:
- 使用 LLM 推理解释结构化或半结构化数据
- 产出类型化输出(例如:带分数与解释的异常报告)
- 将日志与 traces 写入共享的可观测性通道
三者并行运行,从而能快速完成彼此独立的分析。
Fraud Risk Aggregator(风险聚合器)
当专家代理全部完成后,结果进入 Risk Aggregator,执行 fan-in 阶段。它相当于“推理层”:作为一个 LLM 驱动的代理,把多个专家的结构化结果整合成统一评估。
它会输出一个类型化的 RiskAssessment 对象,包含:
risk_score(float)recommendation(例如:LOCK_ACCOUNT或ALLOW)justification(简短的推理总结)
聚合器通常会使用 prompt 模板与 schema 来约束输出一致性,避免不可预测的响应。AI 推理发生在这里,但仍处于“可控且可验证”的边界内。
Deterministic Decision Logic(确定性决策逻辑)
最后,工作流基于聚合结果执行一个确定性规则。例如:
if risk_score > 0.6:
route_to_human("analyst_review")
else:
auto_resolve()
这一层是完全非 AI 的:提供企业流程所需的可预测性、可追溯性与治理能力。
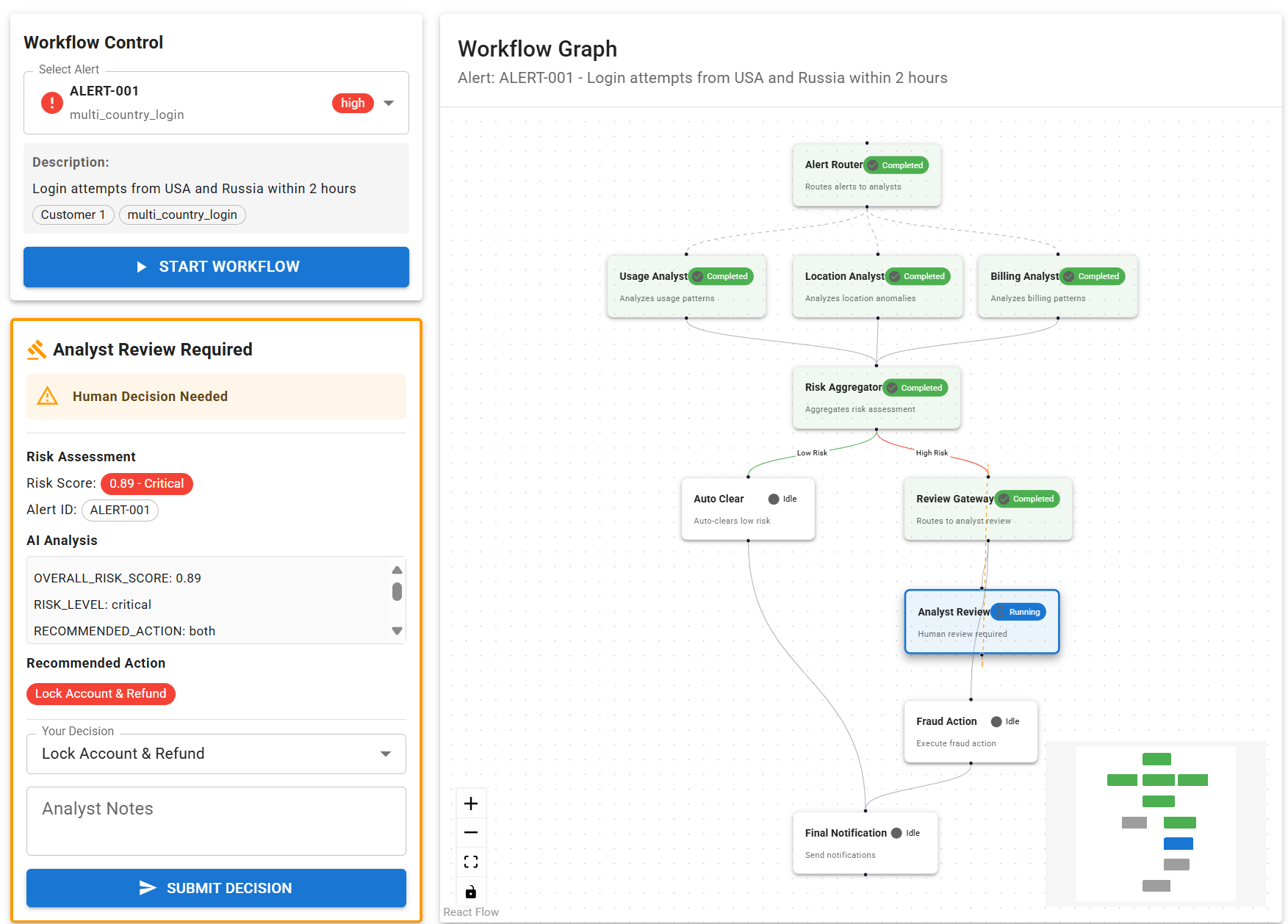
当案例高风险时,系统会 checkpoint 并暂停,等待人工审核。分析师批准或拒绝后,工作流从 checkpoint 继续执行直至完成。这样每条决策路径都能被复现并被记录,使系统既“智能”也“可审计”。
执行特性
Checkpointing(检查点)
每个工作流步骤都可以保存并恢复状态。等待人工审批时会写入 checkpoint;即使进程重启或机器故障,也能从最后状态继续,不丢数据。
框架运行时内置 checkpoint 机制:它会序列化执行上下文以及已完成步骤的输出,并存入持久化后端。保存的状态通常包含:
- 工作流变量
- 已完成步骤输出
- 待执行任务
- 执行元数据
因此可以做到容错恢复与确定性 replay。
Parallelism(并行)
三个专家代理互不依赖,因此工作流用并行执行取代顺序阻塞;运行时会安全地管理并发,按完成顺序收集结果并在 fan-in 合流。
Fault Tolerance and Recovery(容错与恢复)
如果某个代理或执行器失败,运行时可以从 checkpoint 重启该节点,而不重复运行已完成步骤。恢复过程是确定性且幂等的——这对金融/医疗等自动化场景很关键。
Observability(可观测性)
框架会发出:
- 每个节点执行的 OpenTelemetry traces
- 用于仪表盘实时可视化的 WebSocket 事件流
- 结构化审计日志:记录每次代理调用与 LLM 响应
Human in the Loop Integration(人机协同 / HITL)
并非所有决策都应该自动化。这里的工作流包含一个“人工复核节点”,当风险评估较高时触发:节点会挂起执行并等待审批;分析师批准或拒绝后,再从 checkpoint 恢复。
这种模式能在不引入复杂外部流程编排的前提下,把自动化与必要的人类监督融合起来。
实现概览
在 Microsoft Agent Framework 中,欺诈检测工作流以 workflow graph(工作流图) 实现:它由一组连接起来的 executors(节点)组成,定义精确的操作顺序、数据流与控制逻辑。
整体流程可以概括为:
- 将可疑告警 fan-out 给多个领域专家代理(使用、位置、账单)并行分析
- 将并行结果 fan-in 到一个 AI 聚合代理
- 将聚合后的风险评估交给 确定性决策逻辑
- 对高风险案例可选地在 HITL checkpoint 暂停等待人工复核
- 恢复后执行最终的反欺诈动作并通知用户
Fan-Out / Fan-In(并行代理)
这是核心编排模式。
-
Fan-Out: 一条告警被分发到多个 executor 并行执行。在代码里可以写成:
# Create workflow builder builder = WorkflowBuilder() # Fan-out: AlertRouter → Usage, Location, Billing executors builder.add_fan_out_edges(alert_router, [ usage_executor, location_executor, billing_executor ])这表示
AlertRouterExecutor会把同一条告警发送给三个专门的代理(各自使用受限的 MCP 工具),并发完成分析。 -
Fan-In: 工作流等待所有并行分支完成,然后把结果合并到
FraudRiskAggregatorExecutor:# Fan-in: Usage, Location, Billing → Aggregator builder.add_fan_in_edges( [usage_executor, location_executor, billing_executor], aggregator )聚合器作为 LLM 推理代理,会综合各分支发现,计算统一风险分数并给出建议,同时受 schema 约束。
路由与 HITL
当聚合器输出 FraudRiskAssessment 后,工作流应用确定性决策逻辑:
builder.add_switch_case_edge_group(
aggregator,
[
# High risk → Analyst review via ReviewGatewayExecutor
Case(condition=lambda assessment: assessment.overall_risk_score >= 0.6,
target=review_gateway),
# Low risk → Auto clear
Default(target=auto_clear),
],
)
- 高风险 会通过
RequestInfoExecutor路由给人工分析师复核,并在此处 checkpoint,确保可安全暂停/恢复。 - 低风险 由
AutoClearExecutor自动放行。
两条路径最终都会汇聚到 FinalNotificationExecutor,发送客户通知并记录审计轨迹。
这套设计为什么重要
这种模块化、图驱动的设计意味着:
- 并行分析 能随计算资源线性扩展。
- 确定性编排 保证可复现与容错。
- HITL checkpoint 能把自动化与必要的人类监督自然融合。
- 可扩展性:替换代理或新增代理不需要改变编排模式。
应用视图
部署灵活性
原文总结了这套方案在部署层面的可选项:
- Runtime:基于 Microsoft Agent Framework 核心,提供工作流执行、checkpoint 持久化与 tracing。
- Models:代理可调用任何可用的 LLM(通过 Azure OpenAI、Azure AI Foundry 或其他渠道)。
- Storage:checkpoint 与日志可使用常见后端(例如 Azure Blob、PostgreSQL)。
- Security:MCP 工具隔离访问;凭据与密钥不进入 LLM 上下文。
- Monitoring and Observability:OpenTelemetry 数据可对接 Azure Monitor、Grafana 或 Azure AI Foundry。
- 开发者既可以本地跑完整系统,也可以以容器化组件部署到 Azure Kubernetes Service。
扩展这种模式
同样的架构也适用于其他受监管流程,例如:
- 保险理赔审核
- 医疗授权审批
- 贷款核保
- 需要人工复核的文档分类
通常只需要替换“代理定义”和“工具绑定”,编排逻辑可以保持不变。
总结
这个欺诈检测工作流示例展示了一种实用的组合方式:用确定性工作流确保可控、可追溯、可恢复;用 AI 代理在合适的环节做领域推理。
一条告警会 fan-out 到三个专家代理(使用、位置、账单)并行分析;结果 fan-in 给 AI 聚合代理输出类型化的风险评估;最后由确定性规则决定是自动放行还是进入人工复核 checkpoint。整个流程还覆盖了 checkpointing、并行执行、类型安全消息与 OpenTelemetry 可观测性,确保在中断后可从最后状态恢复,形成可靠、可审计、可复现的执行路径。
- 本文作者:BeanHsiang
- 本文链接:https://beanhsiang.github.io/post/2025-10-11-building-human-in-the-loop-ai-workflows-with-microsoft-agent-framework/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. 进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。