使用 Azure AI Foundry 监控生成式 AI 应用
🧭 引言
监控 AI 应用,早就不只是盯着「是否在线」和「有没有报错」这么简单了。面对生成式 AI 的工作负载,团队还需要持续回答三个更关键的问题:
- AI 的输出到底“好不好”(质量、准确性、帮助性)
- 运行成本是多少(尤其是 token 消耗与推理成本)
- 是否足够安全、合规、可控(有无有害输出、策略违规等)
Microsoft 在 Azure AI Foundry 中提供了一套集成式的可观测能力,把 Application Insights、持续评估(continuous evaluation)与可自定义仪表板串起来,从而实现对 AI 应用端到端的可见性;同时也与 Azure Baseline Monitoring Alerts 的思路保持一致。
通过结合 Azure Monitor 的基线告警框架与 AI Foundry 的内置指标/遥测,团队可以更主动地监控并对齐 Microsoft 的 Azure Baseline Monitoring Alerts。
💡 为什么 AI 应用的监控更重要
| 维度 | 传统应用 | 生成式 AI 应用 |
|---|---|---|
| 性能 | API 延迟、失败率、可用性 | 单次模型调用的响应时间、不同模型版本的性能表现 |
| 成本 | 计算、存储 | Token 使用量与模型推理成本 |
| 质量 | 功能正确性 | 回复质量、帮助性、准确性 |
| 安全 | 安全漏洞 | 有害输出检测、策略违规 |
| 漂移 | 版本不一致 | 模型漂移、提示词敏感性变化 |
🎯 生成式 AI 的监控 = 传统指标 + 智能/质量/安全等新维度。
🧩 Azure AI Foundry 的监控能力一览
Azure AI Foundry 采用“分层”的可观测思路:
| 能力 | 说明 | 目的 |
|---|---|---|
| Application Insights 集成 | 将项目连接到 Azure Monitor,用于请求、trace、异常等遥测。 | 采集核心遥测 |
| 内置 Application Analytics 仪表板 | 可视化延迟、token 用量、异常率、响应质量等。 | 快速运维可视化 |
| Agent 持续评估(Continuous Evaluation) | 自动评估 AI 回复的质量、安全性、准确性。 | 质量监控 |
| Kusto(KQL)查询访问 | 用查询深入到原始遥测数据。 | 深度分析 |
| Azure Monitor 告警 | 基于 KQL 结果触发规则(例如 latency > 2s)。 | 主动告警 |
| 可定制 Workbooks | 修改现成仪表板或自建可视化。 | 团队化洞察 |
监控架构可视化概览:
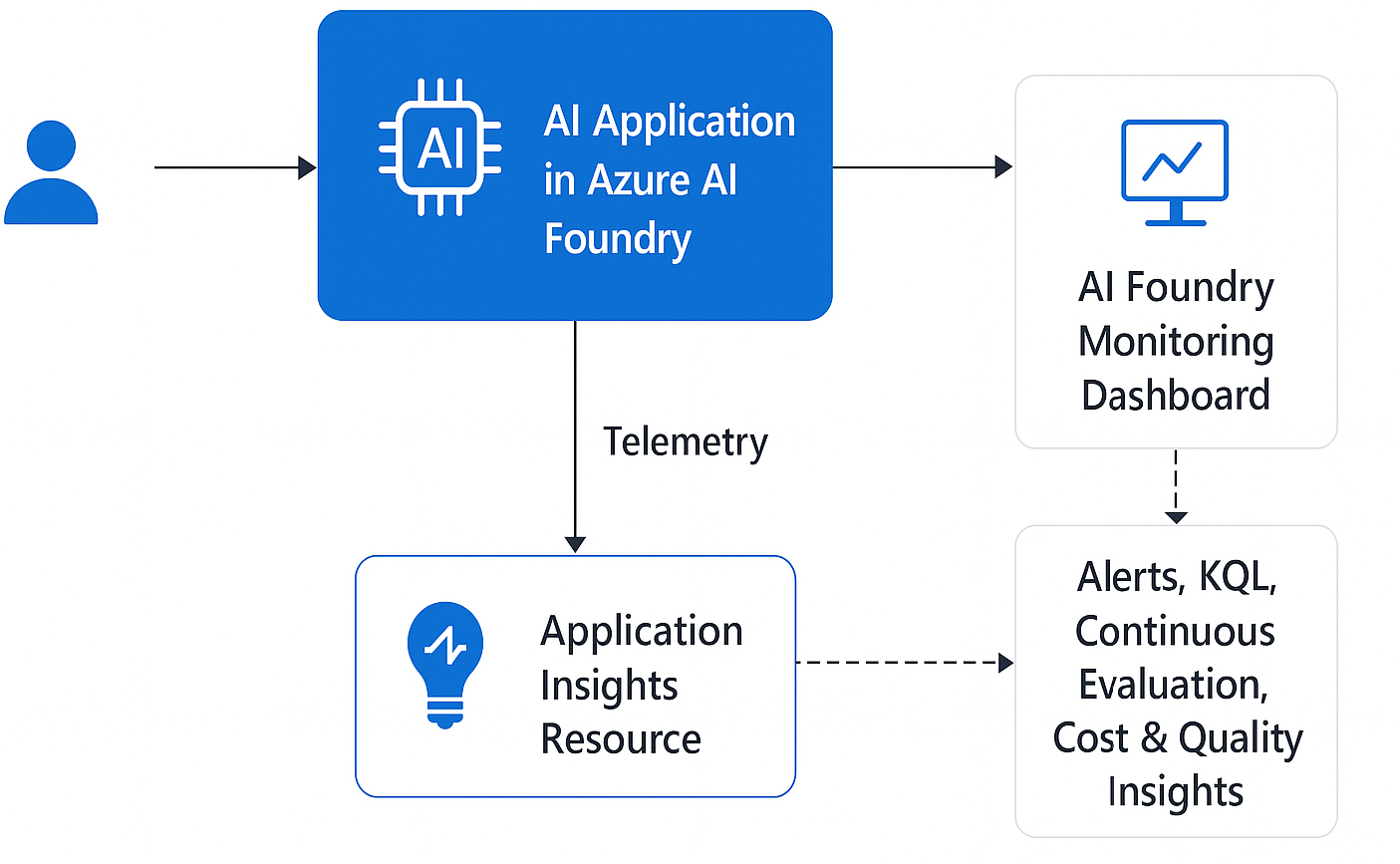
总体来说,Azure AI Foundry 提供了一套完整的监控框架:既覆盖传统的性能指标,也覆盖 token 用量、输出质量与安全等 AI 特有信号。
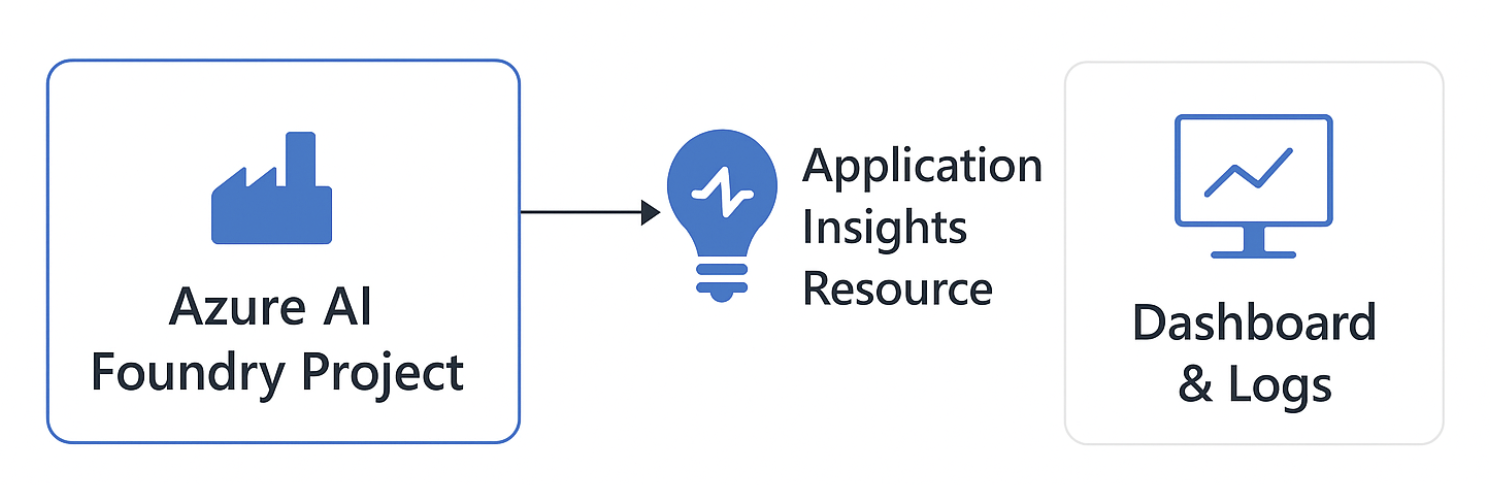
🧩 Step 1 — 将 Azure AI Foundry 连接到 Application Insights
Azure AI Foundry 本身并不存储监控数据——它是通过集成 Azure Monitor Application Insights(属于更广义的 Azure Monitor 体系)来完成监控落地。
完成连接后,AI 应用可以自动上报日志、trace、异常,以及延迟、token 消耗、评估分数等自定义指标。
🔧 连接步骤
- 打开 AI Foundry 项目
- 登录 Azure AI Foundry portal 并进入目标项目。
- 进入 Monitoring
- 在左侧导航中点击 Monitoring → Application Analytics。
- 绑定 Application Insights 资源
- 如果订阅里已经有现成资源,从下拉框选择即可。
- 否则点击 Create new Application Insights resource。
- 选择名称、资源组、区域(尽量与 AI Foundry 项目同区域,以优化延迟)。
- 确认连接
- 连接后,AI 应用的遥测会自动流入。
- 你可以在几分钟后打开 Application Analytics 仪表板,或在 Application Insights → Logs 中验证。
⚙️ Step 2 — 为 AI 应用代码加上埋点(Instrumentation)
把资源连上只是“开闸放水”,想要拿到真正有意义的数据(例如 token 用量、质量分数、延迟),还需要对应用进行埋点。
示例(Python SDK)
from azure.monitor.opentelemetry import configure_azure_monitor
# Configure Application Insights telemetry
configure_azure_monitor(connection_string="InstrumentationKey=<YOUR_KEY>")
# Example: Log token usage or model metadata
logger.info("AI Call", extra={
"customDimensions": {
"model_version": "gpt-4",
"prompt_type": "customer_support",
"input_tokens": 180,
"output_tokens": 256
}
})
像 model_version、prompt_type、user_segment 这类 custom dimensions 很值得加:它们能让仪表板与查询维度更清晰,后续分析会省很多力气。
📊 Step 3 — 使用 Application Analytics 仪表板
当遥测开始流入后,在项目中打开 Monitoring → Application Analytics,常见会看到:
- Latency(每次请求的平均响应时间)
- Token usage(每次调用的输入/输出 token)
- Failure rate and exceptions(失败率与异常)
- Quality score(如果启用了持续评估)
使用建议
- 用右上角的 time range 筛选近期运行。
- 点击任意 tile → “Open Query” 查看背后的 KQL query。
- 克隆或编辑仪表板,加入你们自己的指标。
🔍 Step 4 — 用 Kusto(KQL)做深度分析
需要更深入诊断时,可以打开 Application Insights → Logs,用 KQL 对数据做分析。
常见场景(示例查询为原文节选)
- 识别最慢的端点:
requests | - 追踪 token 用量趋势:
customMetrics | - 监控安全相关分数:
customMetrics |
🚨 Step 5 — 为关键事件设置告警
不要等到出了问题才发现——可以在 Azure Monitor 中配置 alerts。
创建告警规则
- 打开你的 Application Insights 资源。
- 选择 Alerts → Create → Alert rule。
- 使用 KQL query 或内置指标条件,例如:
- Latency > 3 s
- Error rate > 5%
- Token usage > 500K per hour
- 绑定 Action Group(邮件、Microsoft Teams 或 webhook 等)。
可以把整体流程理解为:App Insights → Alert → Teams 通知 → DevOps 处置动作。
🧮 Step 6 — 定期优化与复盘
监控不是“一次配置、永远不用管”。建议按周或按月复盘,确保:
- 成本(token 消耗)仍在预算内
- 质量分数 达到或高于预期
- 延迟 在不同模型版本之间保持稳定
- 安全指标 没有出现策略违规的上升趋势
复盘表格示例
| 指标 | 目标 | 实际 | 趋势 | 动作 |
|---|---|---|---|---|
| Latency (ms) | < 2500 ms | 3100 ms | ⬆️ Increasing | Optimize prompt size |
| Quality Score | > 0.9 | 0.92 | ➡️ Stable | ✅ |
| Token Usage (per hour) | < 400K | 480K | ⬆️ Increasing | Review model selection |
| Safety Violations | < 1% | 0.8% | ➡️ Stable | ✅ |
🧭 Step 7 — 闭环:把监控接回 MLOps
最后,把监控洞察接回 MLOps workflow:
- 质量下降 时,触发重新评估或微调(fine-tuning)流水线
- 成本飙升 时,切换到更轻量的模型(例如 GPT-4o mini)
- 安全问题 出现时,在人工确认前自动下线相关 agent
Monitoring → Alert → Azure DevOps Pipeline / Retraining Workflow → Model Update → Back to Monitoring
- 本文作者:BeanHsiang
- 本文链接:https://beanhsiang.github.io/post/2025-12-08-monitoring-generative-ai-applications-with-azure-ai-foundry/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. 进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
相关文章
- 使用 Foundry Local、Microsoft Foundry 与 Agent Framework 构建混合 AI(下):云端 agent 安全回拨本地私密上下文
- 使用 Foundry Local、Microsoft Foundry 与 Agent Framework 构建混合 AI(上):隐私优先的本地+云端协同
- 使用 Agent Framework 构建带人工审批的多智能体顺序工作流
- 使用 Microsoft Agent Framework 构建 Human-in-the-loop 的 AI 工作流
- 将 Azure AI Foundry 与 Copilot Studio 集成:战略与技术概览