使用 Microsoft Olive 和 Foundry Local 部署自定义模型
在过去的几周里,我一直在探索小语言模型(SLM)的部署之旅。从最初了解 Phi-4 和小语言模型的强大之处,到实践使用 Foundry Local 在本地运行模型,再到学习函数调用,最近还构建了一个完整的多智能体测验应用,其中包含一个协调专家智能体的编排器。
这个测验应用在本地运行得很好,但它依赖于 Foundry Local 目录中的模型——这些模型经过预优化且随时可用。但如果想部署一个不在目录中的模型该怎么办?也许你已经在特定领域的测验数据上微调了一个模型,或者 Hugging Face 上刚发布了一个你想使用的新模型。今天我将展示如何从 Hugging Face 获取一个模型,使用 Microsoft Olive 优化它,在 Foundry Local 中注册它,并在测验应用中运行它。同样的工作流程适用于你可能为特定用例微调的任何模型。
理解部署选项
在深入之前,让我们先了解 SLM 应用程序的部署选项全景。根据目标环境,有几种部署 SLM 应用程序的途径。
三种主要路径
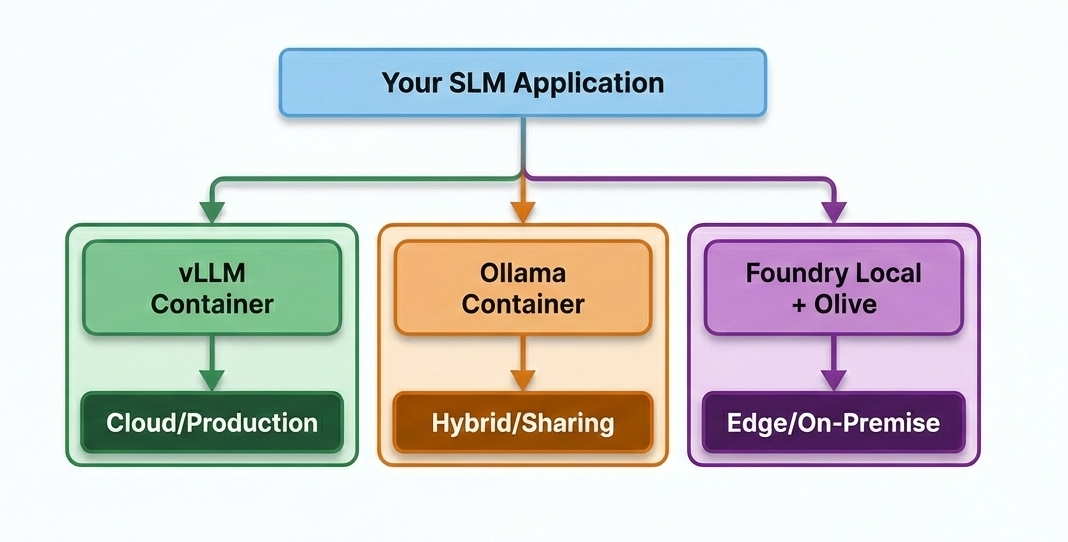
vLLM 是云部署的行业标准——容器化、可扩展、处理许多并发用户。非常适合 Azure VM 或 Kubernetes。
Ollama 提供了一个中间地带——比 vLLM 简单,但仍然提供 Docker 支持,便于共享和部署。
Foundry Local + Olive 是 Microsoft 的边缘优先方法。使用 Olive 优化你的模型,使用 Foundry Local 或自定义服务器提供服务。非常适合本地部署、离线或注重隐私的部署。
为了保持本系列文章的边缘优先主题,我将专注于 Foundry Local 路径。我将使用 Qwen 2.5-0.5B-Instruct——足够小,可以快速优化并演示完整的工作流程。可以把它看作是你在自己的测验数据上微调的模型的替代品。
前置要求
你需要:
- Foundry Local 版本 0.8.117 或更高
- Python 3.10+ 用于测验应用(foundry-local-sdk 需要)
- 单独的 Python 3.9 环境用于 Olive(Olive 0.9.x 有此要求)
使用两个 Python 版本可能看起来有些奇怪,但这反映了一个常见的实际设置:在一个环境中优化模型,在另一个环境中提供服务。优化是一次性的步骤。
安装 Olive 依赖项
在你的 Python 3.9 环境中:
|
|
重要提示: Olive 与 Transformers 5.x 不兼容。必须使用 4.x 版本。
使用 Olive 进行模型优化
Microsoft Olive 是 Hugging Face 模型与 Foundry Local 可服务内容之间的桥梁。它在一个命令中处理 ONNX 转换、图优化和量化。
理解量化
量化通过将权重从高精度浮点转换为低精度整数来减小模型大小:
| 精度 | 大小减少 | 质量 | 最适合 |
|---|---|---|---|
| FP32 | 基线 | 最佳 | 开发、调试 |
| FP16 | 减小 50% | 优秀 | 具有充足 VRAM 的 GPU 推理 |
| INT8 | 减小 75% | 非常好 | 平衡生产 |
| INT4 | 减小 87.5% | 良好 | 边缘设备、资源受限 |
我将使用 INT4 来展示最大压缩。对于具有更好质量的生产环境,可以考虑 INT8——只需在下面的命令中将 –precision int4 更改为 –precision int8。
运行优化
scripts/optimize_model.py 处理两件事:在本地下载模型(以避免身份验证问题),然后运行 Olive。
下载步骤很重要。ONNX Runtime GenAI 模型构建器内部请求 HuggingFace 身份验证,即使对于公共模型也是如此。我们不配置令牌,而是首先使用 token=False 下载模型,然后将 Olive 指向本地路径:
|
|
然后针对本地副本运行 Olive 命令:
|
|
关键标志:–precision int4 将权重量化为 4 位整数,–use_model_builder 读取每个 transformer 层并将其导出为 ONNX,–use_ort_genai 以 Foundry Local 使用的格式输出。
运行它:
|
|
此过程大约需要一分钟。完成后,你将看到输出目录结构。
models/qwen2.5-0.5b-int4/model/
├── model.onnx # ONNX 图 (162 KB)
├── model.onnx.data # 量化的 INT4 权重 (823 MB)
├── genai_config.json # ONNX Runtime GenAI 配置
├── tokenizer.json # 分词器词汇表 (11 MB)
├── vocab.json # Token-to-ID 映射 (2.7 MB)
├── merges.txt # BPE 合并 (1.6 MB)
├── tokenizer_config.json
├── config.json
├── generation_config.json
├── special_tokens_map.json
└── added_tokens.json
总大小:约 838MB——与原始模型相比大幅减小,同时保持了结构化任务(如测验生成)的可用质量。
在 Foundry Local 中注册
模型优化完成后,我们需要在 Foundry Local 中注册它。与云模型注册表不同,这里没有 CLI 命令——你将文件放在正确的目录中,Foundry 会自动发现它们。
Foundry 的模型注册表
|
|
Foundry 按发布者组织模型:
.foundry/cache/models/
├── foundry.modelinfo.json ← 官方模型目录
├── Microsoft/ ← 预优化的 Microsoft 模型
│ ├── qwen2.5-7b-instruct-cuda-gpu-4/
│ ├── Phi-4-cuda-gpu-1/
│ └── ...
└── Custom/ ← 你的模型放在这里
注册脚本
scripts/register_model.sh 脚本做两件事:将所有模型文件复制到 Foundry 缓存,并创建 inference_model.json 配置文件。
关键文件是 inference_model.json——没有它,Foundry 不会识别你的模型:
|
|
PromptTemplate 定义了 Qwen 2.5 期望的 ChatML 格式。{Content} 占位符是 Foundry 在运行时注入实际消息内容的位置。如果你部署的是 Llama 或 Phi 模型,你将使用它们各自的提示模板。
运行注册:
|
|
验证注册
|
|

测试模型
|
|
模型通过 CPU 上的 ONNX Runtime 加载。尝试一个简单的提示来验证它是否响应。
与测验应用集成
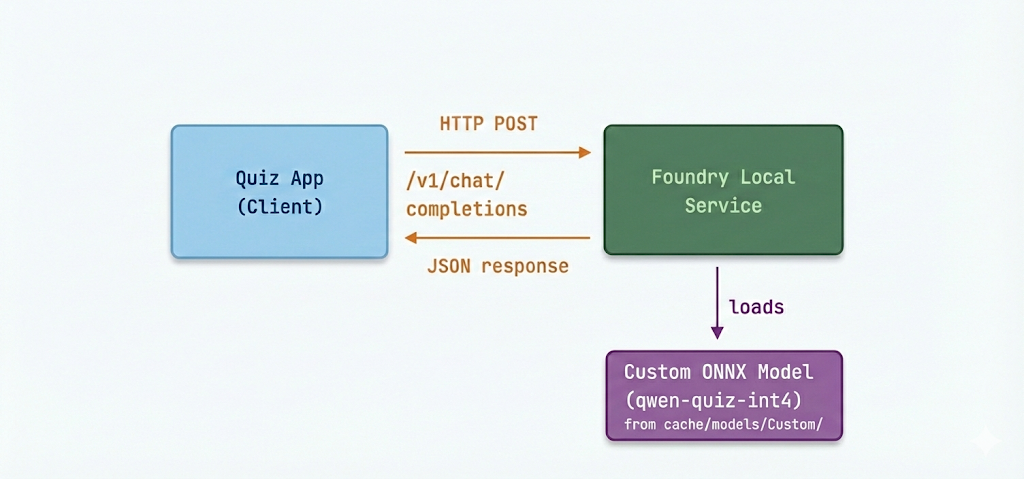
这就是有趣的地方。应用程序级别的更改只需在 utils/foundry_client.py 中修改一行:
|
|
但这一行修改引发了一些值得理解的问题。
问题 1:SDK 无法看到自定义模型
Foundry Local Python SDK 通过在官方目录中查找模型来解析模型——这是一个 Microsoft 发布的模型 JSON 文件。Custom/ 目录中的自定义模型不在该目录中。因此 FoundryLocalManager(“qwen-quiz-int4”) 会抛出"找不到模型"错误,尽管 foundry cache ls 和 foundry model run 都完美工作。
foundry_client.py 中的修复是双代码路径。它首先尝试 SDK(适用于目录模型),当失败并显示"在目录中找不到"错误时,它会回退到直接发现正在运行的服务端点。
工作流程变成两个终端:
终端 1: foundry model run qwen-quiz-int4
终端 2: python main.py
客户端自动发现端点并连接。对于目录模型,现有的 FoundryLocalManager 路径保持不变。
问题 2:工具调用格式
对于目录模型,Foundry 的服务器端中间件会拦截模型输出中的 <tool_call> 标签,并将它们转换为 API 响应中的结构化 tool_calls 对象。这是通过 foundry.modelinfo.json 中的元数据配置的。
对于自定义模型,这些元数据字段不被识别——Foundry 在 inference_model.json 中忽略它们。<tool_call> 标签作为原始文本传递到 response.choices[0].message.content 中。
由于我们的自定义模型输出完全相同的 <tool_call> 格式,我们在 agents/base_agent.py 中添加了一个小的回退解析器——这与我们在函数调用中探索的模式相同。
模型的行为是相同的;只是解析位置发生了变化——从服务器端(Foundry 中间件)到客户端(我们的代码)。
测试部署
模型在一个终端中运行,在另一个终端启动测验应用。
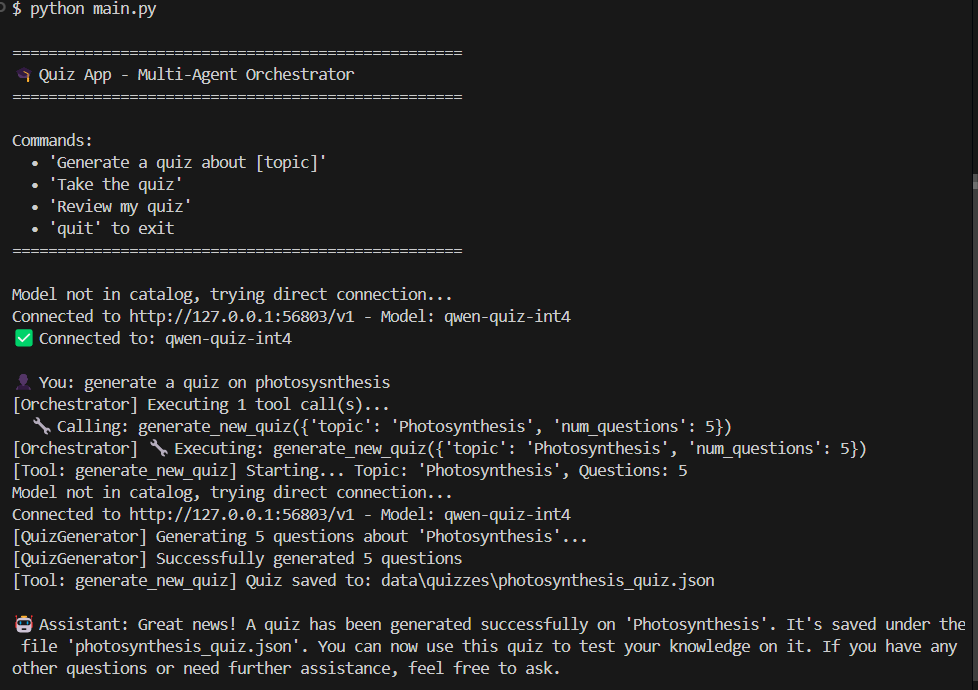
编排器成功调用了 generate_new_quiz 工具,QuizGeneratorAgent 生成了结构良好的测验 JSON。
模型限制
0.5B INT4 模型偶尔会在复杂推理或基本算术方面遇到困难。这是如此小且大量量化的模型的预期行为。对于需要更高准确性的生产用例,可以使用 Qwen 2.5-1.5B 或 Qwen 2.5-7B 以获得更好的质量,或使用 INT8 量化而不是 INT4。部署工作流程保持不变——只需在优化脚本中更改模型名称和精度。
你已经完成的工作
花点时间欣赏一下整个系列的完整旅程:
| 文章 | 你学到了什么 |
|---|---|
| 1. Phi-4 介绍 | 为什么 SLM 重要,性能与大小的权衡 |
| 2. 本地运行 | Foundry Local 设置,基本推理 |
| 3. 函数调用 | 工具使用,外部 API 集成 |
| 4. 多智能体系统 | 编排,专家智能体 |
| 5. 部署 | Olive 优化,Foundry Local 注册,自定义模型部署 |
现在我掌握了构建生产 SLM 应用程序的端到端技能:理解全景、使用 Foundry Local 进行本地开发、使用函数调用的智能体应用、多智能体架构、使用 Olive 进行模型优化,以及将自定义模型部署到边缘。
接下来做什么
下一个逻辑步骤是针对你的领域进行微调。在 USMLE 问题上训练的医学测验导师,在案例法上训练的法律助理,在内部文档上训练的公司入职机器人——使用相同的 Olive 工作流程来优化和部署你的微调模型。我们使用 Foundry Local 注册的相同 ONNX 模型也可以通过 ONNX Runtime Mobile 在移动设备上运行,或者容器化用于服务器端边缘部署。
资源:
- Microsoft Olive — 模型优化工具包
- Foundry Local 文档 — 设置和 CLI 参考
- 为 Foundry Local 编译 Hugging Face 模型 — 官方指南
- ONNX Runtime GenAI — 为 Foundry Local 的推理提供支持
- 边缘 AI 入门 — Microsoft 的 8 模块边缘 AI 课程
原文链接: Deploying Custom Models with Microsoft Olive and Foundry Local
- 原文作者:BeanHsiang
- 原文链接:https://beanhsiang.github.io/post/2026-02-12-deploying-custom-models-with-microsoft-olive-and-foundry-local/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. 进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。