Claude 托管智能体 + Azure:没有人谈论的多云 AI 战略
在过去一年里,我一直在研究生产级 AI 智能体的构建。多智能体系统、RAG 流水线、一个全天候运行在 Mac mini 上的自主编程智能体……这些项目里最难搞的从来不是 AI 本身,而是基础设施。
沙箱隔离、状态管理、工具执行、容器编排、凭据轮换、错误恢复——在智能体真正能做什么有用的事之前,往往需要好几个月的水管工程。
……一个技术老兵工作的点滴记录,专注、沟通、乐在分享!
在过去一年里,我一直在研究生产级 AI 智能体的构建。多智能体系统、RAG 流水线、一个全天候运行在 Mac mini 上的自主编程智能体……这些项目里最难搞的从来不是 AI 本身,而是基础设施。
沙箱隔离、状态管理、工具执行、容器编排、凭据轮换、错误恢复——在智能体真正能做什么有用的事之前,往往需要好几个月的水管工程。
……Azure AI Foundry(前身为 Azure AI Studio)是微软提供的端到端平台,用于构建、测试、部署和监控 AI 代理及应用程序。它将模型、工具、框架和治理能力整合到一个统一的系统中。

现代企业自动化往往需要多个 AI 系统协同完成任务。与其让单一的大型语言模型承担所有工作,Azure AI Foundry 引入了多代理编排机制——让专业化的 AI 代理在工作流中相互协作。
……这篇文章记录的是如何观察和了解 Agent 在现实中的实际运行状态。
Agent 与普通 API 有根本的不同。它不是简单的请求/响应就结束,而是一套多阶段流程:LLM 推理 → 工具调用 → 结果处理 → 再推理。出错时,很难立即看出是哪个阶段因为什么原因失败了。速度慢时,也搞不清楚时间消耗在哪里。在成本方面,更难分析是哪个查询消耗了大量 Token。
……Microsoft Agent Framework 现已集成 Claude Agent SDK,让我们能够构建由 Claude 完整代理能力驱动的 AI 代理。这个集成将 Agent Framework 的一致代理抽象与 Claude 的强大功能结合在一起,包括文件编辑、代码执行、函数调用、流式响应、多轮对话以及模型上下文协议(MCP)服务器集成——目前在 Python 中可用。
我们可以单独使用 Claude Agent SDK 来构建代理。那么为什么要通过 Agent Framework 来使用它呢?以下是主要原因:
……在过去的几周里,我一直在探索小语言模型(SLM)的部署之旅。从最初了解 Phi-4 和小语言模型的强大之处,到实践使用 Foundry Local 在本地运行模型,再到学习函数调用,最近还构建了一个完整的多智能体测验应用,其中包含一个协调专家智能体的编排器。
这个测验应用在本地运行得很好,但它依赖于 Foundry Local 目录中的模型——这些模型经过预优化且随时可用。但如果想部署一个不在目录中的模型该怎么办?也许你已经在特定领域的测验数据上微调了一个模型,或者 Hugging Face 上刚发布了一个你想使用的新模型。今天我将展示如何从 Hugging Face 获取一个模型,使用 Microsoft Olive 优化它,在 Foundry Local 中注册它,并在测验应用中运行它。同样的工作流程适用于你可能为特定用例微调的任何模型。
……我发现 Microsoft Agent Framework 现在与 GitHub Copilot SDK 集成,让我们能够构建由 GitHub Copilot 驱动的 AI 代理。这个集成将 Agent Framework 一致的代理抽象与 GitHub Copilot 的强大功能结合在一起,包括函数调用、流式响应、多轮对话、Shell 命令执行、文件操作、URL 获取以及 Model Context Protocol (MCP) 服务器集成 —— 所有这些功能在 .NET 和 Python 中都可用。
你可以单独使用 GitHub Copilot SDK 来构建代理。那么为什么要通过 Agent Framework 来使用它呢?以下是几个关键原因:
……微软研究院发布了 OptiMind,这是一个基于 AI 的系统,能够将复杂决策问题的自然语言描述转换为优化求解器可执行的数学公式。它解决了运筹学中长期存在的一个瓶颈问题:将业务意图转换为混合整数线性规划通常需要专业建模人员和数天的工作。
OptiMind-SFT 是 gpt-oss transformer 系列中的一个专业化 200 亿参数专家混合模型。每个 token 约激活 36 亿参数,因此推理成本更接近中型模型,同时保持较高的容量。上下文长度为 128,000 tokens,这允许在单个请求中处理长规范和多步推理轨迹。
……agent_framework 是微软推出的 Python 库,专门用于构建 AI 代理应用程序。我在研究这个框架时发现,它为聊天代理、工作流、工具调用和中间件提供了非常优雅的抽象。核心类包括实现 AgentProtocol 协议的代理、用于在工作流中运行代理的执行器、用于聊天输入/输出的消息,以及用于定义工作流拓扑的构建器。例如,AgentProtocol 是一个结构化接口,任何代理都必须遵循它(比如 ChatAgent 就实现了这个接口)。
在研究 AI Agent 的过程中,我发现了一个有趣的现象:虽然质量至关重要,但成本和执行时间(推理时间)往往成为 Agent 管道中最大的争议点。
像 GPT-5.2 或 Gemini 3 Pro 这样的"推理"大语言模型确实可以提高质量。然而,我注意到它们往往存在生成时间长和 token 使用量增加的问题,从而推高了成本和延迟。当 Agent 需要在每个任务中做出大量决策时,这种权衡就会成为一个重大瓶颈。
……
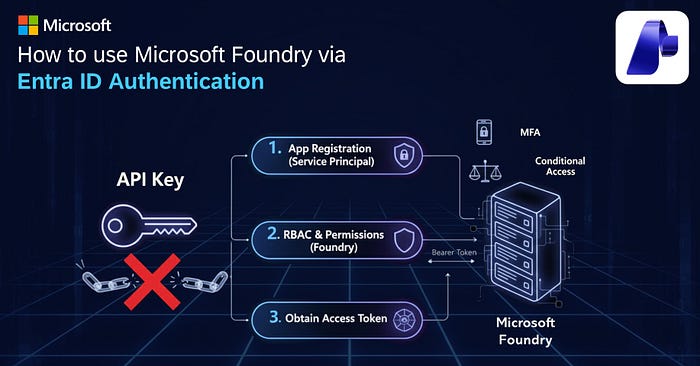
Microsoft Foundry(2025 年 11 月之前称为 Azure AI Foundry)在使用服务时提供两种身份验证方式,包括 LLM 推理:基于密钥的身份验证和 Entra ID 身份验证。虽然基于密钥的身份验证更容易使用,但我想在这里分享使用 Entra ID 身份验证的优势,以及如何开始使用它的分步说明!
基于密钥的身份验证快速简单……只需从 Foundry 门户获取 API 密钥,将其作为 header 插入 api-key 名称下,就可以开始使用了!然而,由于其简单性,基于密钥的身份验证也存在一些限制。主要限制之一是安全性。虽然基于密钥的身份验证很简单,但它是"全有或全无"的访问方式——任何拥有该密钥的人都可以执行资源允许的任何操作。